Friday, November 30, 2012
"The UNIX System" from the AT&T Archives
Film (produced in 1982) includes Brian Kernighan demonstrating how to write a spell check command in shell, interviews with Ken Thompson, Dennis Ritchie, and much more.
MartUX: Tab Updated!
For those of you waiting for consolidated information on the SVR4 SPARC OpenIndiana iniative - MartUX now has a Network Management Tab!
A copy of it is now found here:
 MartUX is Martin Bochnig's SVR4 release of OpenIndiana on SPARC. MartUX was based upon OpenSolaris. Originally released only on sun4u architecture, it now also runs as a Live-DVD under sun4v.
MartUX is Martin Bochnig's SVR4 release of OpenIndiana on SPARC. MartUX was based upon OpenSolaris. Originally released only on sun4u architecture, it now also runs as a Live-DVD under sun4v.
[http] MartUX Announcement: September 27, 2012
[http] MartUX OpenIndiana 151 Alpha Live-DVD Wiki
[http] Martin Bochnig's Blog for MartUX, OpenIndiana SPARC port from OpenSolaris
[http] Martin Bochnig Twitter account
[http] MartUX site (down since storage crash)
[http] MartUX site snapshot from archive.org
[html] Network Management MartUX articles
A copy of it is now found here:
[http] MartUX Announcement: September 27, 2012
[http] MartUX OpenIndiana 151 Alpha Live-DVD Wiki
[http] Martin Bochnig's Blog for MartUX, OpenIndiana SPARC port from OpenSolaris
[http] Martin Bochnig Twitter account
[http] MartUX site (down since storage crash)
[http] MartUX site snapshot from archive.org
[html] Network Management MartUX articles
Thursday, November 29, 2012
TribbliX: Tab Updated!
For those waiting for consolidated information - TribbliX now has a consolidated tab on Network Management blog!
A current snapshot can be seen here:
 Tibblix is Peter Tribble's incarnation of an SVR4 based OS, leveraging Illumos at the core. This is an Intel only distribution at this point. Tribblix is a brand-new pre-release, downloaded as a live-dvd, and based upon OpenIndiana.
Tibblix is Peter Tribble's incarnation of an SVR4 based OS, leveraging Illumos at the core. This is an Intel only distribution at this point. Tribblix is a brand-new pre-release, downloaded as a live-dvd, and based upon OpenIndiana.
[html] Tribblix Announcement: October 23, 2012
[html] Distribution Home Page
[html] Download Page
[html] Installation Guide
[html] Basic Usage Starting Pointers
[html] Peter Tribble Blog
[html] Peter Tribble Solaris Desktop Blog
[html] Network Management Tribblix Posts
A current snapshot can be seen here:
[html] Tribblix Announcement: October 23, 2012
[html] Distribution Home Page
[html] Download Page
[html] Installation Guide
[html] Basic Usage Starting Pointers
[html] Peter Tribble Blog
[html] Peter Tribble Solaris Desktop Blog
[html] Network Management Tribblix Posts
Wednesday, November 28, 2012
MartUX: Second SVR4 SPARC Release!


In July 2012, Martin started his new work, of updating MartUX on SPARC. In August, Martin indicated he was "working day and night" to continue progress on a new distribution cut. The question was broached on the SPARC distribution again, in September. The shift from IPS to Live-DVD occurred, in order to release a product. People discuss buying of older SPARC hardware and reserving some equipment, in preparation for the new distribution. Martin posts some screenshots of the new distribution on September 10. Discussions about under 10% savings between gzip-5 and gzip-9 occur, and the drawback of great CPU usage during the packaging phase. By September 27, a MartUX DVD ISO was made available.
By the end of September of 2012, there was an indication a new distribution based upon OpenSolaris code base and OpenIndiana. OpenIndiana now uses a new living codebase of Illumos to augment the static code base of OpenSolaris. The OpenIndiana community had screenshots and instructions noted on their 151a release wiki of the MartUX LiveDVD. A short, but useful articles appeared on some of the industry wires such as Phoronix. MartUX OpenIndiana SPARC release is also now booting on the first sun4v or newer "T" architectures from Sun/Oracle!
October 4 hits, Martin starts the process of formalizing the distribution. The goal is to move from his previous MartUX distribution name. Martin, however, had a catastrophic disk failure. His struggling was noted on a different list, but he comments about it on the OpenIndiana list, suggesting using triple-mirrors, and disconnecting the third mirror to ensure a solid backup.
Martin mentioned on October 2nd through twitter that Dave Miller was working on an installer and pkgadd. There was little sign of Martin posting in November on the OpenIndiana list, after his hard disk issues, but an occasional tweet here or there. Martin set up a separate blogspot for SPARC OI work. The martux.org web site is down, as of the end of November, although a snapshot of the content is still available on archive.org. We hope all is well, as he continues his unbelievable work on a SPARC release.
Tuesday, November 27, 2012
Tribblix: Second SVR4 Intel Release!
Network Management announced the pre-release of Tribblix at the end of October 2012. There is a new release which happened early November 2012.
Note - the user community can now download an x64 version called 0m1.
Oh, how we are waiting for a SVR4 SPARC release!
Wednesday, November 21, 2012
SPARC at 25: Past, Present and Future (Replay)
In October, Network Management published a reminder concerning:
If you missed it, you can view the replay here, thanks to YouTube!
Thursday, November 1, 2012 Event: 11:00 AM
Lunch: 12:00 Noon
Computer History Museum
1401 North Shoreline Blvd.
Mountain View, California 94043
SPARC at 25: Past, Present and Future
Presented by the Computer History Museum Semiconductor Special Interest Group
If you missed it, you can view the replay here, thanks to YouTube!
| Panelists presenting include industry giants: Andy Bechtolsheim, Rick Hetherington, Bill Joy, David Patterson, Bernard Lacroute, Anant Argawal |
Thursday, November 1, 2012 Event: 11:00 AM
Lunch: 12:00 Noon
Computer History Museum
1401 North Shoreline Blvd.
Mountain View, California 94043
Monday, November 19, 2012
ZFS, Metaslabs, and Space Maps

ZFS, Metaslabs, and Space Maps
Abstract:
File systems are a memory structure which represents data, often stored on persistent media such as disks. For decades, the standard file system used by multi-vendor operating systems was the Unix File System, or UFS. While this file system served well for decades, storage continued to grow exponentially, and existing algorithms could not keep up. With the opportunity to re-create the file system, Sun Microsystems worked the underlying algorithms to create ZFS - but different data structures were used, unfamiliar to the traditional computer scientist.
Space Maps:
One of the most significant driving factors to massive scalability is dealing with free space. Jeff Bonwick of Sun Microsystems, now of Oracle, described some of the challenges to existing space mapping algorithms about a half-decade ago.
Bitmaps
The most common way to represent free space is by using a bitmap. A bitmap is simply an array of bits, with the Nth bit indicating whether the Nth block is allocated or free. The overhead for a bitmap is quite low: 1 bit per block. For a 4K blocksize, that's 1/(4096\*8) = 0.003%. (The 8 comes from 8 bits per byte.)
For a 1GB filesystem, the bitmap is 32KB -- something that easily fits in memory, and can be scanned quickly to find free space. For a 1TB filesystem, the bitmap is 32MB -- still stuffable in memory, but no longer trivial in either size or scan time. For a 1PB filesystem, the bitmap is 32GB, and that simply won't fit in memory on most machines. This means that scanning the bitmap requires reading it from disk, which is slower still.
Clearly, this doesn't scale....B-trees
Another common way to represent free space is with a B-tree of extents. An extent is a contiguous region of free space described by two integers: offset and length. The B-tree sorts the extents by offset so that contiguous space allocation is efficient. Unfortunately, B-trees of extents suffer the same pathology as bitmaps when confronted with random frees....Deferred frees
One way to mitigate the pathology of random frees is to defer the update of the bitmaps or B-trees, and instead keep a list of recently freed blocks. When this deferred free list reaches a certain size, it can be sorted, in memory, and then freed to the underlying bitmaps or B-trees with somewhat better locality. Not ideal, but it helps....Space maps: log-structured free lists
Recall that log-structured filesystems long ago posed this question: what if, instead of periodically folding a transaction log back into the filesystem, we made the transaction log be the filesystem?
Well, the same question could be asked of our deferred free list: what if, instead of folding it into a bitmap or B-tree, we made the deferred free list be the free space representation?That is precisely what ZFS does. ZFS divides the space on each virtual device into a few hundred regions called metaslabs. Each metaslab has an associated space map, which describes that metaslab's free space. The space map is simply a log of allocations and frees, in time order. Space maps make random frees just as efficient as sequential frees, because regardless of which extent is being freed, it's represented on disk by appending the extent (a couple of integers) to the space map object -- and appends have perfect locality. Allocations, similarly, are represented on disk as extents appended to the space map object (with, of course, a bit set indicating that it's an allocation, not a free)....
When ZFS decides to allocate blocks from a particular metaslab, it first reads that metaslab's space map from disk and replays the allocations and frees into an in-memory AVL tree of free space, sorted by offset. This yields a compact in-memory representation of free space that supports efficient allocation of contiguous space. ZFS also takes this opportunity to condense the space map: if there are many allocation-free pairs that cancel out, ZFS replaces the on-disk space map with the smaller in-memory version.

Metaslabs:
One may as, what exactly is metaslab and how does it work?
Adam Levanthal, formerly of Sun Microsystems, now at Delphix working on an open-source ZFS and DTrace implementations, describes metaslabs in a little more detail:
For allocation purposes, ZFS carves vdevs (disks) into a number of “metaslabs” — simply smaller, more manageable chunks of the whole. How many metaslabs? Around 200.
Why 200? Well, that just kinda worked and was never revisited. Is it optimal? Almost certainly not. Should there be more or less? Should metaslab size be independent of vdev size? How much better could we do? All completely unknown.
The space in the vdev is allotted proportionally, and contiguously to those metaslabs. But what happens when a vdev is expanded? This can happen when a disk is replaced by a larger disk or if an administrator grows a SAN-based LUN. It turns out that ZFS simply creates more metaslabs — an answer whose simplicity was only obvious in retrospect.
For example, let’s say we start with a 2T disk; then we’ll have 200 metaslabs of 10G each. If we then grow the LUN to 4TB then we’ll have 400 metaslabs. If we started instead from a 200GB LUN that we eventually grew to 4TB we’d end up with 4,000 metaslabs (each 1G). Further, if we started with a 40TB LUN (why not) and grew it by 100G ZFS would not have enough space to allocate a full metaslab and we’d therefore not be able to use that additional space.
Fragmentation:
I remember reading on the internet all kinds of questions such as "is there a defrag utility for ZFS?"
While the simple answer is no, it seems the management of metaslabs inherent to ZFS attempts to mitigate fragmentation, by rebuilding the freespace maps quite regularly, and offers terrific improvements in performance as file systems become closer to being full.
Expand and Shrink a ZFS Pool:
Expansion of a ZFS pool is easy. One can swap out disks or just add them on.
What trying to shrink a file system? This may be, perhaps, the most significant heart-burn with ZFS. Shrinkage is missing.
Some instructions on how RAID restructure or shrinkage could be done were posted by Joerg at Sun Microsystems, now Oracle, but shrinkage requires additional disk space (which is what people are trying to get, when they desire a shrink.) Others have posted procedures for shrinking root pools.
One might speculate the existence (and need to reorganize of destroy) the metaslab towards the trailing edges of the ZFS file system pool may introduce the complexities, since these are supposed to only grow, and hold data sequentially in time order.

Network Management Implications:
I am at the point now, where I have a need to divide up a significant application pool into smaller pools, to create a new LDom on one of my SPARC T4-4's. I need to fork off a new Network Management instance. I would love for the ability to shrink zpools in the near future (Solaris 10 Update 11?) - but I am not holding out much hope, considering ZFS existed over a half-decade, there has been very little discussion on this point, and how metslabs and freespace are managed.
Wednesday, November 14, 2012
IBM POWER 7+ Better Late than Never?
In August 2011, when Oracle released the SPARC T4, IBM decided to release something, but it was not a CPU chip, but a roadmap... problem was - IBM POWER 7+ was late.
 |
| Courtesy, The Register |
Thank you for the IBM August 2011 POWER Roadmap tha the public marketplace has been begging for... did we miss the POWER7+ release??? A POWER 7 February 2010 launch would have POWER 7+ August 2011 launch (and today is August 31, so unless there is a launch in the next 23 hours, it looks late to me.)
 |
| IBM Flex p260 CPU Board, courtesy The Register |
Disposition of POWER 7+
Just announced, via TPM at The Register, is the ability to provision an IBM p260 with new POWER 7+ processors!
IBM finally released POWER 7+, in one system, 15 months late. How underwhelming. |
| IBM POWER 7+ die image, courtsy The Register |
Disposition of POWER 8
The question that no one is asking: Where is POWER 8, according to the IBM roadmap?
The POWER 8, according to the roadmap, should be released roughly February of 2013. Why release the POWER 7+ just 3 months shy of releasing the POWER 8? This suggests a problem for IBM.
The 2013 timeframe is roughly when Oracle suggested they may start releasing SPARC T5 platforms, ranging from 1 to 8 sockets. The POWER 8 surprisingly has a lot of common features with the SPARC T5 -the POWER 8 may have gone back to the drawing board to copy SPARC T5. How late is POWER 8?
Conclusions:
Whatever happened, something broke at IBM. For a piece of silicon to be delayed 15 months, IBM must have needed to bring POWER 7+ back to the proverbial drawing board. The big question is - did IBM need to bring POWER 8 back to the drawing board, as well?
Automatic Storage Tiering
 |
| Image courtesy: WWPI. |
Abstract:
Automatic Storage Tiering or Hierarchical Storage Management is the process of placing the most data onto storage which is most cost effective, while meeting basic accessibility and efficient requirements. There has been much movement over the past half-decade in storage management.
Early History:
When computers were first being built on boards, RAM (most expensive) held the most volatile data while ROM held the least changing data. EPROM's provided a way for users to occasionally change mostly static data (requiring a painfully slow erasing mechanism using light and special burning mechanism using high voltage), placing the technology in a middle tier. EEPROM's provided a simpler way to update data on the same machine, without removing the chip for burning. Tape was created, to archive storage for longer periods of time, but it was slow, so it went to the bottom of the capacity distribution pyramid. Rotating disks (sometimes referred to as rotating rust) was created, taking a middle storage tier. As disks became faster, the fastest disks (15,000 RPM) moved towards the upper part of the middle tier while slower disks (5,400RPM or slower) moved towards the bottom part of the middle tier. Eventually, consumer-grade (not very reliable) IDE and SATA disks became available, occupying the higher areas of the lowest tier, slightly above tape.
 |
| Logo Sun Microsystems |
In the early 2000's, Sun Microsystems started to invest more in flash technology. They anticipated a revolution in storage management, with the increase performance of a technology called "Flash", which is little more than EEPROM's. These became known as Solid State Drives or SSD's. In 2005, Sun released ZFS under their Solaris 10 operating system and started adding features that included flash acceleration.

 |
| Sun Funfire 4500 aka Thumper, courtesy Sun Microsystems |
For the next 5-7 years, the industry experienced hand-wringing with what to do with the file system innovation introduced by Sun Microsystems under Solaris ZFS. More importantly, ZFS is a 128 bit file system, meaning massive data storage is now possible, on a scale that could not be imagined. The OS and File System were also open-sourced, meaning it was a 100% open solution.
With this technology, built into all of their servers, This became increasingly important as Sun released mid-range storage systems based upon this technology with a combination of high capacity, lower price, and higher speed access. Low end solutions based upon ZFS also started to hit the market, as well as super-high-end solutions in MPP clusters.
 |
| Drobo-5D, courtesy Drobo |
Recent Vendor Advancements - Drobo:
A small-business centric company called Data Robotics or Drobo released a small RAID system with an innovative feature: add drives of different size, system adds capacity and reliability on-the-fly, with the loss of some disk space. While there is some disk space loss noted, the user is protected against drive failure on any drive in the RAID, regardless of size, and any size drive could replace the bad unit.
 |
| Drobo-Mini, courtesy Drobo |
The challenge with Drobo - it is a proprietary hardware solution, sitting on top of a fairly expensive hardware, for the low to medium end market. This is not your $150 raid box, where you can stick in a couple of drives and go.

Recent Vendor Advancements - Apple:
Not to be left out, Apple was going to bundle ZFS into every Apple Macintosh they were to ship. Soon enough, Apple canceled their ZFS announcement, canceled their open-source ZFS announcement, placed job ads for people to create a new file system, and went into hybernation for years.
Apple recently released a Mac OSX feature they referred to as their Fusion Drive. Mac Observer noted:
"all writes take place on the SSD drive, and are later moved to the mechanical drive if needed, resulting in faster initial writes. The Fusion will be available for the new iMac and new Mac mini models announced today"Once again, the market was hit with an innovative product, bundled into an Operating System, not requiring proprietary software.

Implications for Network Management:
With continual improvement in storage technology, this will place an interesting burden on Network, Systems, and Storage Management vendors. How does one manage all of these solutions in an Open way, using Open protocols, such as SNMP?
The vendors to "crack" the management "nut" may be in the best position to have their product accepted into existing heterogeneous storage managed shops, or possibly supplant them.
Tuesday, November 13, 2012
Monday, November 12, 2012
ARM, Itanium, x64, and SPARC Processor Wars Update
 |
| Courtesy, The Register |
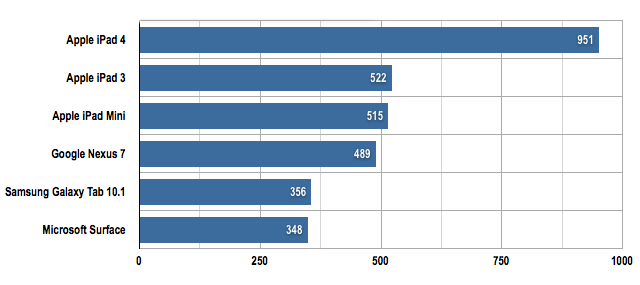
Apple iPad 4 Wi-Fi only tablet review
Beyond the screen, the iPad 4 delivers considerably more oomph than its predecessors. The Geekbench testing app showed that the iPad 3’s performance was much the same as the iPad 2’s, but the new model scores considerably higher: 1766 to the iPad 2’s score of 763. That’s in part because the chip is better, but also due to a 40 per cent increase in CPU clock speed.
Despite that, there’s no degradation in battery life - up to ten hours, says Apple, and I concur. If that’s due to a bigger power cell inside
 |
| Courtesy, International Business Times |
Apple Rumored to Abandon Intel for Its Own Chip
Intel has not been able to ignore rumors that Apple is considering switching some of its Mac's Intel processors to its own A-series of mobile chips, saying it would be a remiss to be dismissive of the rumors.
According to Apple Insider, the claims came on Friday from the Japanese site Macotakara, who successfully predicted the release of the iPad 2 in March, saying that new thunderbolt-equipped MacBook Airs powered by an A5 processor were being tested.

Foxconn, the... manufacturer of kit for Apple, Amazon, Sony, Nintendo, and others, is exploring the possibility of building plants in the US – Detroit and Los Angeles, to be specific.
Those aforementioned market watchers, however, say not to expect your next iPhone or iPad to be made in America – Apple products are too complex to be built by mere 'Mercans.
 |
| Intel Itanium 9500 die image, courtesy The Register |
Intel to slip future Xeon E7s, Itaniums into common socket
The installed bases of HP-UX, NonStop, and OpenVMS users can breathe a sigh of relief if they were hitting a performance ceiling, and so can other server makers such as Bull, NEC, and Fujitsu that have proprietary operating systems that also run on Itanium iron.
The bigger sigh of relief is that Intel is converging the Xeon and Itanium processor and system designs such that future Xeon E7 chips and "Kittson" Itanium processors will share common elements – and, more importantly, share common sockets.
This is something that Intel has been promising for years, and something that HP – the dominant seller of Itanium-based systems – has been craving, as evidenced by its Project Kinetic. Convergence was the plan of record for HP in June 2010 – nine months ahead of the Oracle claim that Itanium was going the way of all flesh – and HP wanted to converge its ProLiant and Integrity server platforms, which used x86 and Itanium processors, respectively. A common socket helps that effort in a big way
 |
| Courtesy: HWSW |
Oracle: two new SPARC chips next year, and three more under construction
In the first half of 2013, the SPARC T5. Heydar performance during the first SPARC-based systems affected T5 chip - the processor itself to Oracle in August Hot Chips conference, explained in further detail when I got to know of it is based on the company's servers are under testing labs. The insert describing the HWSW you guessed, the T4-based machines favorable market acceptance due to either the end of 2013 can expect the T5 launch of Oracle, Heydar, however, clearly stated: the T5-based machines in 2013 in the first half appear commercially.
S3 is a statement of up to 8 processor cores capable of running parallel threads, manufacturing technology development, however, due to the T5-8 instead of 16 cores is the L3 cache size is doubled to 8 megabytes increased. The memory controller also doubled the number of Oracle, we have four instead of two found in the T5, which are standard DDR3-1066 memory modules continue to be handled. Even the T4 was part of two on-board PCI Express x8 controller from its predecessor, however, was supported only in version 2.0, but the new processor PCI Express Gen3 standard used by Oracle, which is twice the bandwidth, in addition to both separate data management unit was.
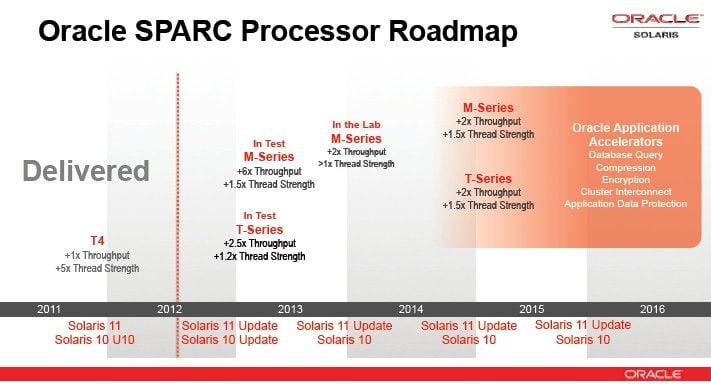 |
| Oracle SPARC Roadmap October 2012, courtesy The Register |
Oracle's mighty SPARC plug fries Fujitsu, bigs up new SPARC M4 processor
Oracle, to its credit, has been perfectly blunt about its long-term Sparc server roadmap: it very clearly outlined its goals with rough timelines. That is more than rivals IBM, Intel and Hewlett-Packard do with their high-end system roadmaps, which can be found if you mooch around the internet long enough for someone to accidentally posts something interesting.
And in the M4 presentation, which Oracle refused to share even though it knew the data was out there, we see that the new chip is a beefy version of a Sparc T series chip: it sports six S3 cores that debuted with the eight-core Sparc T4 processors and are used, in a modified form, in the forthcoming Sparc T5 chips. Those cores will share a 48MB L3 cache, a lot more than the 8MB of shared L3 cache used in the 16-core Sparc T5 processors. Presumably the S3 cores used in the M4 have the same 16KB L1 instruction and 16KB L1 data caches, and 128KB of L2 cache, that each S3 core has on the Sparc T4 and T5 processors.
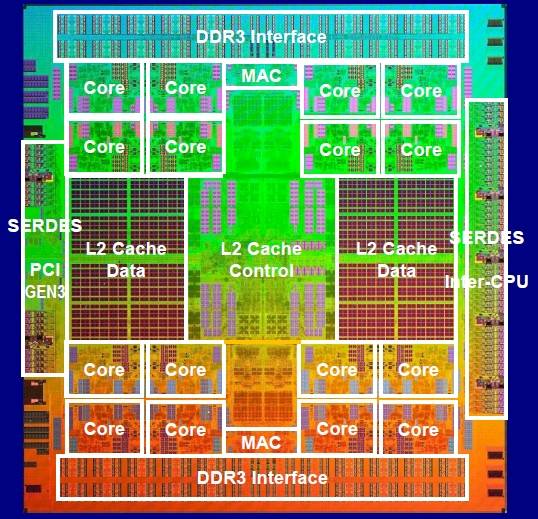
Fujitsu to embiggen iron bigtime with Sparc64-X
with the Sparc64-X processors, which will converge the vanilla and fx versions of the Sparc64 chips into a single products, explained Takumi Maruyama, who is in charge of processor development within Fujitsu's Enterprise Server business unit.
The core has been modified to support the HPC-ACE instructions that accelerated parallel processing and also now includes special accelerators for encryption and other functions – a feature that Fujitsu calls "software on a chip" and akin to the accelerators that Intel, IBM, and Oracle have put into their high-end processors to boost encryption, hashing, and other algorithms.
The Sparc64-X also, thankfully, supports hardware-assisted virtualization, something that has been sorely missing from the Sparc64 series... The chip supports the Sparc V9 instruction set and the extensions to it that Fujitsu has created...
The Sparc64-X core has a deeper pipeline, which enables a higher clock frequency on the processor compared to the Sparc64-VII+, a better branch prediction scheme, bigger queues and floating point registers, more aggressive out-of-order execution, a two-port, multi-banked L1 cache (with twice the bus size and more L1 cache throughput), and a richer set of execution units.
There are two integer execution units, another two virtual address adders that can do double duty as execution units, and four floating point units that can do math and graphics functions. This is twice the number of the integer and floating point units that the Sparc64-VII+ chip had.
Network Management Implications:
Oracle seemed to be correct about Itanium proverbially "going the way of the dinosaur." The common socket seems to be the next move in migration from Intel 64 bit Itanium to the AMD created and Intel copied x64 architecture.
The expression from some analysts that SPARC's life expectancy was limited was certainly pre-mature, appearing to be set to out-live Intel Itanium, and forcing Intel to keep it's x86 line alive much longer than they ever intended. The move by AMD to move the Intel x86 architecture to 64 bits, with the successful seamless migration of SPARC from 32 bit to 64 bit processing were key drivers in forcing Intel to rethink the sunset of x86.
With Apple releasing ARM tablets, fully two to three times faster than competing tablets, one might wonder how long it will be until Apple starts releasing laptops, desksides, desktops, and servers based upon it's own ARM engineering and discard Intel x64? With rumors of MacBook Air's based upon Apple's ARM chipset, this could be a very interesting question. More software seems to be appearing under MacOSX ARM based iOS deviation, rather Intel based MacOSX .
SPARC seems to be proverbially "on the march" with 2 original SPARC vendors (Sun, now owned by Oracle, and Fujitsu) continuing to develop SPARC processors into the distant future, each showing innovation as well as "keeping up with the times" with virtualization.
For businesses continuing to look for a stable environment to build platforms which scale, for long-term network management investments, SPARC continues to be a reasonable investment for long term deployments. Multi-platform and multi-vendor network management seems to be "in the cards" for a long time, if people decide to build to standards, and if vendors decide it is in their best interest to support standards.
Wednesday, November 7, 2012
Solaris 10: Update 11 Coming Soon!

As previously noted in Rick Hetherington's interview, there appears to be a Solaris 10 Update 11, near ready to be released.
While Oracle recently released Solaris 11.1, the rest of us are waiting for Solaris 10 refresh. The main driver appears to be the SPARC T5 support, since this release was mentioned during Rick's interview.
Since most network management platforms run under SPARC Solaris 10 - this is an important update. It ensures that managed services providers targeting network management will be able to get the latest SPARC T5 hardware - to get their much desired platform performance boost. Being able to manage 2.5x the number of devices in a similar price-point means excellent opportunity to be more competitive in bids.
Oracle needs to provide incentives to Network Management ISV's (such as EMC SMARTS) to port their software to Solaris 11, for Solaris 11 to be considered a Tier 1 supported platform. Oracle's forever-support of Solaris 10 is only a stop-gap measure. The SPARC T5 and Solaris 10 Update 11 can not come too soon!
Monday, November 5, 2012
Can Oracle REALLY Increase Throughput by 6x?
Can Oracle REALLY Increase Throughput by 6x?
During some SPARC road map discussions, a particular anonymous IBM POWER enthusiast inquires:
This is a very interesting question... how does one get to 600% throughput increase with the release of the "M4" SPARC processor? One must consider where engineering is moving from and moving towards.

[from] SPARC64-VII+ (code-named M3)
- 4 cores per socket
- 2 thread per core
- 8 threads per socket

[to] M4 S3 Cores (based upon T4 S3 cores)
- 6 cores per socket (conservative)
- 8 threads per core (normative)
- 48 threads per socket

How to Get There:
Core swap results in 6x thread increase... now that we understand this is purely a mathematical question with definitive end result, the question REALLY is:

Of course, it is not only about the hardware, software has a lot to do with it.

Oracle does not appear that far off, from producing the numbers they suggest, with standard applications. They have the technology to do every step, from thread performance acceleration, to storage performance accleration, to I/O performance acceleration, to file system acceleration, to application performance acceleration.
A cursory and objective look at the numbers demonstrate how it is possible - it is not solely about the cores... but the cores are key to understanding how it is possible.

{kind=link}
{kind=link}
During some SPARC road map discussions, a particular anonymous IBM POWER enthusiast inquires:
How... are 192 S3 cores going to provide x6 throughput of 128 SPARC64-VII+ cores?The Base-Line:
This is a very interesting question... how does one get to 600% throughput increase with the release of the "M4" SPARC processor? One must consider where engineering is moving from and moving towards.

[from] SPARC64-VII+ (code-named M3)
- 4 cores per socket
- 2 thread per core
- 8 threads per socket

[to] M4 S3 Cores (based upon T4 S3 cores)
- 6 cores per socket (conservative)
- 8 threads per core (normative)
- 48 threads per socket
How to Get There:
Core swap results in 6x thread increase... now that we understand this is purely a mathematical question with definitive end result, the question REALLY is:
How can EACH S3 threads perform on-par with a SPARC VII+ thread?Let's speculate upon this question:
- Increasing cores by 50% increase in throughput by 50%
Threads no longer need to perform on-par, although a 50% per-thread increase is projected. - Increase clock rate to 3.6GHz provides
~300% faster per-thread throughput over T1 threads. - Out-of-Order Execution
Another significant increase in throughput over T1-T3 threads. - Increase memory bandwidth over old T processors
Provides opportunity to ~2x socket throughput for instructions & data. - Increase memory bandwidth in throughput over previous SPARC64 V* series
The movement from VII+ based DDR2 to DDR3 offers throughput improvement opportunity - Increase cache
Provides faster per-thread throughput opportunities with S3, but could increase thread starvation. - Decrease cores
Reduce number of cores & threads in a socket, to ensure all thread can run at 100% capacity
Of course, it is not only about the hardware, software has a lot to do with it.
- Produce more database operations (i.e. integer) in hardware, instead of in software, specialized applications such as Oracle RDBMS perform faster on nearly every operation.
- Add compression in hardware
I/O throughput increases 500% to 1000% with no CPU impact.
Oracle 11g RDBMS or Solaris ZFS /w compression hosting any databases see benefit. - Solaris ZFS support of LogZilla (ZFS ZIL Write Cache)
Regular file system applications experience extremely high file system write throughput. - Solaris ZFS support of ReadZilla (ZFS Read Cache)
Regular file system applications experience extremely high file system read throughput.

Oracle does not appear that far off, from producing the numbers they suggest, with standard applications. They have the technology to do every step, from thread performance acceleration, to storage performance accleration, to I/O performance acceleration, to file system acceleration, to application performance acceleration.
A cursory and objective look at the numbers demonstrate how it is possible - it is not solely about the cores... but the cores are key to understanding how it is possible.
Solaris 11.1 Released!
Solaris is a long-lived operating system, dating back to the BSD days of Sun Microsystems, absorbing SVR4 UNIX from AT&T during the dot-com economic expansion, moving Open Source under the waning days of Sun Microsystems, becoming the first Cloud OS after Oracle's acquisition. During this past year, new additions have occurred to the flagship OS, most recently called Solaris 11.1.
Announcement:
Solaris 11.1 was announced during the October OpenWorld 2012. A variety of features were listed in the Solaris 11.1 "whatsnew" PDF which was made available.
- Installation
- Support for a new set of role-based authentication control (RBAC) profiles and authorizations for managing the Automated Instal (AI) service, including the profile Install Service Management.
- Automated Installer (AI) command line (installadm) supports 3 new options, update-service, update-profile, and set-service.
- Ability to specify manifest location with system boot argument.
- Install to iSCSI target LUNs added to interactive installers (AI).
- Automated Installers (AI) support automatically connect to Oracle support services using Oracle Configuration Manager and Oracle Auto Service Request.
- Packaging
- A 4x speedup on systems with 20 zones for parallel zone update.
- System Configuration
- New options extract and delcust for svccfg(1M) to help diff and apply customizations to other systems.
- Improvements to svccfg editprop to ease making changes via text editor.
- svcbundle(1M) command eases SMF manifest and profile creation (NO XML! WOO HOO!)
- New pfedit utility allows Administrators to delegate ability to auditably edit administrative files without privileged mode.
- New rsyslog daemon can be enabled by disabling svc:/system/system-log:default and enabling svc:/system/system-log:rsyslog services.
- Virtualization
performance has been increased by up to 90 percent, while write performance is up to 6x
- Zones asier to create and manage.
- Increased resource management & monitoring of Zones.
- P2V migration of Solaris 10 Environment.
- Path of Fiber Channel or iSCSI device added to zonecfg(1M) encapsulates zone into own zpool for better encapsulation and portability.
- Zone install time decreased 27 percent.
- Zone attach time decreased 91 percent.
- Per-fstype kernel statistic (kstat) for each Zone.
- Global Zone exclusive kstat activity reporting.
- Extend secure remote administration via Remote Administration Daemon (RAD) to Zones.
- The lofi devices, used by zones to access & share now experiences read and write performance gains of 90% and 6x, respectively.
Launch:
Hope you see/saw the Solaris 11.1 Launch Event on November 7, 2012!
Sunday, November 4, 2012
SPARC T5: Architect Rick Hetherington
 |
| [SPARC T5 image, courtesy Oracle Corporation] |
Rich Hetherington discusses in video and and deep-dive interview regarding the new SPARC T5 processor from Oracle.
Some of the question highlights:
- Q: What were the design objectives of the SPARC T5 processor?
- Q: So what’s new in the SPARC T5?
- Q: This is mainly a performance increase story then?
- Q: Does the SPARC T5 also support both single-threaded and multi-threaded applications?
- Q: Was there anything in the design process that surprised you, or did things go the way you expected?
- Q: And how do you know which workloads you want to model on?
- Q: What do you mean when you say trace?
- Q: What do you consider innovative in the SPARC T5?
- Q: What kinds of applications will benefit the most from the SPARC T5?
- Q: What about the security features in the T5?
- Q: I’d like to know if there was any kind of optimization with Solaris 11.
- Q: And the Solaris binary compatibility still applies?
- Q. What's the most important thing you want customers to know about the SPARC T5 processor?
Subscribe to:
Posts (Atom)