Tuesday, October 18, 2011
OracleWorld: Some Presentations
OracleWorld: Some Presentations
For those of you who missed Oracle OpenWorld, these may be of interest to Network Management and Telephone Infrastructure Carrier Providers.
A variety of presentations occurred at Oracle OpenWorld 2011:
[html] 2011-10 - Oracle Openworld Blog
[html] 2011-10-05 - Larry Ellison Keynote
Oracle Openworld 2011
Live Streaming and Recorded
[html] 2011-10-11 - Oracle Sun ZFS Storage Appliance Launch
Phil Bullinger, Senior Vice President of Storage
[html] 2011-08-29 - Oracle SunBlade 6000 Modular System - Introduction
Marc Shelley, Senior Manager, Sun Blade Management Team
[html] 2011-08-29 - Oracle SunBlade 6000 Modular System - Front Chassis
Marc Shelley, Senior Manager, Sun Blade Management Team
[html] 2011-08-29 - Oracle SunBlade 6000 Modular System - Rear Chassis
Marc Shelley, Senior Manager, Sun Blade Management Team
[pdf] 2011-10 - SPARC Strategy
Masood Heydari, Senior Vice President, SPARC Systems Development
[pdf] 2011-10 - Next Generation SPARC Processor
An In-Depth Technical Review
Rick Hetherington, Vice President of Microelectronics
Greg Grohoski, Senior Director of Microelectronics
[pdf] 2011-10 - An Oracle White Paper
Oracle's SPARC T4-1, SPARC T4-2, SPARC T4-4, and SPARC T4-1B Server Architecture
Sunday, October 16, 2011
ZFS: A Multi-Year Case Study in Moving From Desktop Mirroring (Part 2)

Abstract:
ZFS was created by Sun Microsystems to innovate the storage subsystem of computing systems by simultaneously expanding capacity & security exponentially while collapsing the formerly striated layers of storage (i.e. volume managers, file systems, RAID, etc.) into a single layer in order to deliver capabilities that would normally be very complex to achieve. One such innovation introduced in ZFS was the ability to provide inexpensive limited life solid state storage (FLASH media) which may offer fast (or at least greater deterministic) random read or write access to the storage hierarchy in a place where it can enhance performance of less deterministic rotating media. This paper discusses the use of various configurations of inexpensive flash to enhance the write performance of high capacity yet low cost mirrored external media with ZFS.
Case Study:
A particular Media Design House had formerly used multiple external mirrored storage on desktops as well as racks of archived optical media in order to meet their storage requirements. A pair of (formerly high-end) 400 Gigabyte Firewire drives lost a drive. An additional pair of (formerly high-end) 500 Gigabyte Firewire drives experienced a drive loss within one month later. A media wall of CD's and DVD's was getting cumbersome to retain.
First Upgrade:
A newer version of Solaris 10 was released, which included more recent features. The Media House was pleased to accept Update 8, with the possibility of supporting Level 2 ARC for increased read performance and Intent Logging for increase write performance.
The Media House did not see the need to purchase flash for read or write logging at this time. The mirrored 1.5 Terabyte SAN performed adequately.

Second Upgrade:
The Media House started becoming concerned, about 1 year later, when 65% of their 1.5 Terabyte SAN storage was burned through.
Ultra60/root# zpool list NAME SIZE USED AVAIL CAP HEALTH ALTROOT zpool2 1.36T 905G 487G 65% ONLINE -The decision to invest in an additional pair of 2 Terabyte drives for the SAN was an easy one. The external Seagate Expansion drives were selected, because of the reliability of the former drives, and the built in power management which would reduce power consumption.
Additional storage was purchased for the network, but if there was going to be an upgrade, a major question included: what kind of common flash media would perform best for the investment?

Multiple Flash Sticks or Solid State Disk?
Understanding that Flash Media normally has a high Write latency, the question in everyone's mind is: what would perform better, an army of flash sticks or a solid state disk?
This simple question started what became a testing rat hole where people ask the question but often the responses comes from anecdotal assumptions. The media house was interested in the real answer.
Testing Methodology
It was decided that the copying of large files to/from large drive pairs was the most accurate way to simulate the day to day operations of the design house. This is what they do with media files, so this is how the storage should be tested.
The first set of tests surrounded testing the write cache in different configurations.
- The USB sticks would each use a dedicated 400Mbit port
- USB stick mirroring would occur across 2 different PCI buses
- 4x consumer grade 8 Gigabyte USB sticks from MicroCenter were procured
- Approximately 900 Gigabytes of data would be copied during each test run
- The same source mirror was used: the 1.5TB mirror
- The same destination mirror would be used: the 2TB mirror
- The same Ultra60 Creator 3D with dial 450MHz processors would be used
- The SAN platform was maxed out at 2 GB of ECC RAM
- The destination drives would be destroyed and re-mirrored between tests
- Solaris 10 Update 8 would be used
# Check patch releaseThe Base Test: No Write Cache
Ultra60/root# uname -a
SunOS Ultra60 5.10 Generic_141444-09 sun4u sparc sun4u
# check OS release
Ultra60/root# cat /etc/release
Solaris 10 10/09 s10s_u8wos_08a SPARC
Copyright 2009 Sun Microsystems, Inc. All Rights Reserved.
Use is subject to license terms.
Assembled 16 September 2009
# check memory size
Ultra60/root# prtconf | grep Memory
Memory size: 2048 Megabytes
# status of zpool, show devices
Ultra60/root# zpool status zpool2
pool: zpool2
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zpool2 ONLINE 0 0 0
mirror ONLINE 0 0 0
c4t0d0s0 ONLINE 0 0 0
c5t0d0s0 ONLINE 0 0 0
errors: No known data errors
A standard needed to be created by which each additional run could be tested against. This base test was a straight create and copy.
ZFS is a tremendously fast system for creating a mirrored pool under. A 2TB mirrored poll takes only 4 seconds on an old dual 450MHz UltraSPARC II.
# Create mirrored pool of 2x 2.0TB drivesThe data to be copied with source and destination storage is easily listed.
Ultra60/root# time zpool create -m /u003 zpool3 mirror c8t0d0 c9t0d0
real 0m4.09s
user 0m0.74s
sys 0m0.75s
# show source and destination zpools
Ultra60/root# zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
zpool2 1.36T 905G 487G 65% ONLINE -
zpool3 1.81T 85.5K 1.81T 0% ONLINE -
The copy of over 900 GB between mirrored USB pairs takes about 41 hours.
# perform copy of 905GBytes of data from old source to new destination zpool
Ultra60/root# cd /u002 ; time cp -r . /u003The time to destroy the 2 TB mirrored pool holding 900GB of data was about 2 seconds.
real 41h6m14.98s
user 0m47.54s
sys 5h36m59.29s
# erase and unmount new destination zpoolAnother Base Test: Quad Mirrored Write Cache
Ultra60/root# time zpool destroy zpool3
real 0m2.19s
user 0m0.02s
sys 0m0.14s
The ZFS Intent Log can be split from the mirror onto higher throughput media, for the purpose of speeding writes. Because this is a write cache, it is extremely important that this media is redundant - a loss to the write cache can result in a corrupt pool and loss of data.
The first test was to create a quad mirrored write cache. With 2 GB of RAM, there is absolutely no way that the quad 8 GB sticks would ever have more than a fraction flash used, but the hope is that such a small amount of flash used would allow the commodity sticks to perform well.
The 4x 8GB sticks were inserted into the system, they were found, formatted (see this article for additional USB stick handling under Solaris 10), and the system was now ready to accept them for creating a new destination pool.
Creation of 4x mirror ZFS Intent Log with 2TB mirror took longer - 20 seconds.
# Create mirrored pool with 4x 8GB USB sticks for ZIL for highest reliabilityThe new zpool is clearly composed of a 4 way mirror.
Ultra60/root# time zpool create -m /u003 zpool3 \
mirror c8t0d0 c9t0d0 \
log mirror c1t0d0s0 c2t0d0s0 c6t0d0s0 c7t0d0s0
real 0m20.01s
user 0m0.77s
sys 0m1.36s
# status of zpool, show devicesNo copy was done using the quad mirrored USB ZIL, because this level of redundancy was not needed.
Ultra60/root# zpool status zpool3
pool: zpool3
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zpool3 ONLINE 0 0 0
mirror ONLINE 0 0 0
c8t0d0 ONLINE 0 0 0
c9t0d0 ONLINE 0 0 0
logs
mirror ONLINE 0 0 0
c1t0d0s0 ONLINE 0 0 0
c2t0d0s0 ONLINE 0 0 0
c6t0d0s0 ONLINE 0 0 0
c7t0d0s0 ONLINE 0 0 0
errors: No known data errors
A destroy of the 4 way mirrored ZIL with 2TB mirrored zpool still only took 2 seconds.
# destroy zpool3 to create without mirror for highest throughputThe intention of this setup was just to see if it was possible, ensure the USB sticks were functioning, and determine if adding an unreasonable amount of redundant ZIL to the system created any odd performance behaviors. Clearly, if this is acceptable, nearly every other realistic scenario that is tried will be fine.
Ultra60/root# time zpool destroy zpool3
real 0m2.19s
user 0m0.02s
sys 0m0.14s
Scenario One: 4x Striped USB Stick ZIL
The first scenario to test will be the 4-way striped USB Stick ZFS Intent Log. With 4 USB sticks, 2 sticks on each PCI bus, each stick on a dedicated USB 2.0 port - this should offer the greatest amount of throughput from these commodity flash sticks, but the least amount of security from a failed stick.
# Create zpool without mirror to round-robin USB sticks for highest throughput (dangerous)The zpool creation was 19 seconds, destroying almost 3 seconds, but the copy decreased from 41 to 37 hours or about 10% savings... with no redundancy.
Ultra60/root# time zpool create -m /u003 zpool3 \
mirror c8t0d0 c9t0d0 \
log c1t0d0s0 c2t0d0s0 c6t0d0s0 c7t0d0s0
real 0m19.17s
user 0m0.76s
sys 0m1.37s
# list zpools
Ultra60/root# zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
zpool2 1.36T 905G 487G 65% ONLINE -
zpool3 1.81T 87K 1.81T 0% ONLINE -
# show status of zpool including devices
Ultra60/root# zpool status zpool3
pool: zpool3
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zpool3 ONLINE 0 0 0
mirror ONLINE 0 0 0
c8t0d0 ONLINE 0 0 0
c9t0d0 ONLINE 0 0 0
logs
c1t0d0s0 ONLINE 0 0 0
c2t0d0s0 ONLINE 0 0 0
c6t0d0s0 ONLINE 0 0 0
c7t0d0s0 ONLINE 0 0 0
errors: No known data errors
# start copy of 905GB of data from mirrored 1.5TB to 2.0TB
Ultra60/root# cd /u002 ; time cp -r . /u003
real 37h12m43.54s
user 0m49.27s
sys 5h30m53.29s
# destroy it again for new test
Ultra60/root# time zpool destroy zpool3
real 0m2.77s
user 0m0.02s
sys 0m0.56s
Scenario Two: 2x Mirrored USB ZIL on 2TB Mirrored Pool
Adding quad mirrored ZIL offered a 10% boost with no redundancy, what if we added a pair of mirrored USB ZIL sticks, to offer write striping for speed and mirroring for redundancy?
# create zpool3 with pair of mirrored intent USB intent logsThe results were almost identical. A 10% improvement in speed was measured. Splitting the commodity 8GB USB sticks into a mirror offered redundancy without lacking performance.
Ultra60/root# time zpool create -m /u003 zpool3 mirror c8t0d0 c9t0d0 \
log mirror c1t0d0s0 c2t0d0s0 mirror c6t0d0s0 c7t0d0s0
real 0m19.20s
user 0m0.79s
sys 0m1.34s
# view new pool with pair of mirrored intent logs
Ultra60/root# zpool status zpool3
pool: zpool3
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zpool3 ONLINE 0 0 0
mirror ONLINE 0 0 0
c8t0d0 ONLINE 0 0 0
c9t0d0 ONLINE 0 0 0
logs
mirror ONLINE 0 0 0
c1t0d0s0 ONLINE 0 0 0
c2t0d0s0 ONLINE 0 0 0
mirror ONLINE 0 0 0
c6t0d0s0 ONLINE 0 0 0
c7t0d0s0 ONLINE 0 0 0
errors: No known data errors
# run capacity test
Ultra60/root# cd /u002 ; time cp -r . /u003
real 37h9m52.78s
user 0m48.88s
sys 5h31m30.28s
# destroy it again for new test
Ultra60/root# time zpool destroy zpool3
real 0m21.99s
user 0m0.02s
sys 0m0.31s
If 4 USB sticks are to be purchased for ZIL, don't bother striping all 4, split them into mirrored pairs and get your 10% boost in speed.

Scenario Three: Vertex OCZ Solid State Disk
Purchasing 4 USB sticks for the purpose of a ZIL starts to approach the purchase price of a fast SATA SSD drive. On the UltraSPARC II processors, the drivers for SATA are lacking, so that is not necessarily a clear option.
The decision test a USB to SATA conversion kit with the SSD and run a single SSD SIL was made.
# new flash disk, format
Ultra60/root# format -e
Searching for disks...done
AVAILABLE DISK SELECTIONS:
...
2. c1t0d0
/pci@1f,2000/usb@1,2/storage@4/disk@0,0
...
# create zpool3 with SATA-to-USB flash disk intent USB intent log
Ultra60/root# time zpool create -m /u003 zpool3 mirror c8t0d0 c9t0d0 log c1t0d0
real 0m5.07s
user 0m0.74s
sys 0m1.15s
# show zpool3 with intent log
Ultra60/root# zpool status zpool3
pool: zpool3
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zpool3 ONLINE 0 0 0
mirror ONLINE 0 0 0
c8t0d0 ONLINE 0 0 0
c9t0d0 ONLINE 0 0 0
logs
c1t0d0 ONLINE 0 0 0
The single SSD over a SATA to USB interface provided a 20% boost in throughput.
# run capacity test
Ultra60/root# cd /u002 ; time cp -r . /u003
real 32h57m40.99s
user 0m52.04s
sys 5h43m13.31s
In Conclusion
Using commodity parts, a ZFS SAN can have the write performance boosted using USB sticks by 10% as well as by 20% using an SSD. The SSD is a more reliable device and better choice for ZIL.
Thursday, October 13, 2011
Death of Two Titans: Jobs and Ritchie
The Mac Observer published last week:

[Steve Jobs]
Steve Jobs was famous for the creation of Apple Computer with the Apple II and Macintosh, as well as popular consumer electronics like the iPod, iPhone, and iPad.
Electronista publishes today:

Dennis Ritchie published the book "The C Programming Language" in 1978 with Brian Kernighan, after the C Language was developed at Bell Labs. The language is often referred to as "K&R C". This language was also used in the development of the UNIX Operating System with Ken Thompson.

[President Clinton awarding National Medal of Technology in 1998 to Dennis Ritchie and Ken Thompson]
Nearly all modern operating systems are now based upon C. These three are the grandfathers of modern computers. Even Steve Job's Macintosh Operating System, MacOS X, is based on UNIX and C.

I could never give justice to the likes of Steve Jobs or Dennis Ritchie in this blog, but at least I can reference them. Unlike the license place, they "lived free and died - UNIX".
May God rest their souls, which longed for excellence and perfection.
U.S. President Barack Obama issued a statement on the passing of Steve Jobs Wednesday calling the Apple cofounder one of America’s greatest innovators. Mr. Jobs passed away sometime on Wednesday, an event that had lead to many luminaries offering statements and remembrances about the iconic executive. The president, an iPad user, also praised Mr. Jobs for having, “changed the way each of us sees the world.”
[Steve Jobs]
Steve Jobs was famous for the creation of Apple Computer with the Apple II and Macintosh, as well as popular consumer electronics like the iPod, iPhone, and iPad.
Electronista publishes today:
Just one week after the tech industry was hit with the news of Steve Jobs' death, computer scientist Dennis Ritchie has also passed. The unfortunate news was announced by friend and colleague Rob Pike, who notes that Ritchie died at his home after a "long illness." The 70-year-old Harvard graduate and veteran of Lucent Technologies and Bell Labs was credited with authoring the C programming language.
Dennis Ritchie published the book "The C Programming Language" in 1978 with Brian Kernighan, after the C Language was developed at Bell Labs. The language is often referred to as "K&R C". This language was also used in the development of the UNIX Operating System with Ken Thompson.
[President Clinton awarding National Medal of Technology in 1998 to Dennis Ritchie and Ken Thompson]
Nearly all modern operating systems are now based upon C. These three are the grandfathers of modern computers. Even Steve Job's Macintosh Operating System, MacOS X, is based on UNIX and C.
I could never give justice to the likes of Steve Jobs or Dennis Ritchie in this blog, but at least I can reference them. Unlike the license place, they "lived free and died - UNIX".
May God rest their souls, which longed for excellence and perfection.
Wednesday, October 12, 2011
RIM: Unbelievably Down, Unbelievably Long

RIM: Unbelievably Down, Unbelievably Long
Abstract:
Sun had a saying "The Network is The Computer". When a network is down, the computer is nearly useless. RIM is now experiencing "The Network is The BlackBerry". The BlackBerry is pretty much useless without the network. The impact to the market may be terrible.
A Short History:
Apple had made an attempt to build a "Personal Digital Assistant" market in 1987. The "Newton" seemed to target educators and students. Some other vendors released competing products, but none of them seem to be successful. It was a product "before it's time".
In 1996, U.S. Robotics created the "Palm Pilot", new digital assistant. This became successful, the technology moved to 3Com, Handspring, Palm.
Nokia started the merging of personal digital assistant software into the phone in the late 1990's, later on with some weak web browsing capability. Nokia cobbled together their phone with HP's software. The term "smart phone" was created. Ericson released a concept PDA and phone in 1997 with the eventual culmination of a touchscreen "smartphone" in 2000. The phone used the SymbianOS.

[2008-2009 Market Trend]
RIM seems to have virtually created the "smart phone" market in 1999. The merging of digital personal assistant and cell phone seemed to drive their success. Their primary target community was business and financial segments, who could afford an uplifted phone cost for the side benefit of becoming more efficient. The product offering was a success.
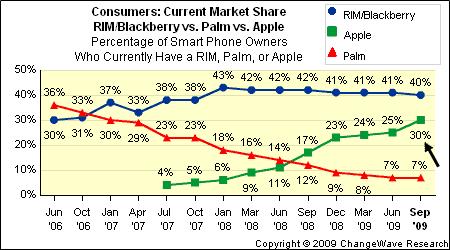
[2006-2009 Market Trend]
In the early 2000's, Palm released a merged their personal digital assistant with cell phone technology. The "smart phone" market had a new competitor. Eventually, the technology was purchased by HP, where it resides today.

[2009-2010 Market Trend]
Apple computer started designing the iPhone in 2005 and released it in January 2007. Their new "smart phone" (i.e. iPhone), which was speculated to be a "flop" since it did not come with a keyboard. The product targeted the "creative" and "youth" segments, merging functionality from their wildly popular iPod portable music & video playing devices. Also bundled was the first real web browser - until this point, internet HTTP experience was poor. The product offering was a success and placed pressure on RIM by slowly intruding into the business and financial sectors, while other vendors (like Palm and Microsoft) were getting devastated.

[2010-2011 Market Trend]
Google started a parallel track to Apple. They purchased Android, Inc in late 2005 and eventually released an operating system called "Android" in late 2007, after the wildly successful Apple iPhone introduction earlier that year. Phone manufacturers jumped on-board Android, trying to get a chunk of the "smart phone" market, without the heavy investment and innovation performed by companies like Palm, RIM, and Apple.

Cell phone giant, Nokia, had been losing market share. Microsoft had been losing marketshare in the mobile phone operating system market. These two shrinking titans agreed in April 2011 to combine forces - Nokia providing hardware with Microsoft's OS. It could stem the bleeding from both companies or the two shrinking titans might become one sinking titanics.
The Nightmare Scenario
RIM had "secret sauce" embedded into it's BlackBerry communicator - all communciation from their phones were carried over their network infrastructure, in addition to the telephone carrier's infrastructure. RIM's encrypted network allowed them to provide add-on services, as well as security to their business users.
This week, there has been a multi-day outage for BlackBerry users, across the globe. The problem was with a switch in THEIR INFRASTRUCTURE - which means it is not the fault of a telephone company. Only BlackBerry users are affected - while the rest of the SmartPhone market is unaffected.
Don't Lie To The Customer
RIM's "secret sauce" is appearing to be their "achilles heel". Without RIM and their network, the BlackBerry is pretty much useless.
This very week, there is BlackBerry training happening in my corporate headquarters, and when questions regarding the BlackBerry difficulties came up - the trainer said "there must be something wrong with your company's network."
The truth is not only out, but it appears the issue is isolated to THEIR customer network.
Bad Discusssions
When investors and analysts start to talk about situations like these, the language does not get any worse than this.
Jefferies analyst Peter Misek crushed RIM in a research note today. His memo to activists was that RIM's turnaround will take a long time...Surviving because there are no other options on the table when investors are thinking about chopping your comany up into little pieces it not a good place to be.Specifically, Misek said that RIM can't be broken up until its migration to QNX is complete in roughly six months. Meanwhile, a management change is difficult. Motorola Mobility CEO Sanjay Jha would be a candidate to lead RIM, but he's highly thought of at Google. Other executives at Apple and Microsoft are largely locked up from going to RIM. PC makers, smartphone rivals, and other takeover options look slim.
Add it up and RIM's only real option at the moment is to execute well and bolster momentum for the BlackBerry. The outages aren't helping that cause.

When Sharks Attack
During this very week, Apple had announced their long-anticipated iPhone 4S, a faster SmartPhone with build-in "Cloud Syncronization" - Apple will no longer require a user to have a computer in order to keep their phones backed up or syncronized with music. Apple's phone will no longer require Apple or a PC in order to get the full functionality of it. Apple's open-sourced MacOSX based iPhone was poised for serious growth, without the BlackBerry disaster.
Google is about to feed the market, with it's army of hardware manufacturers, with more open-sourced Android phones while sinking-faster-than-a-brick Nokia and Microsoft are trying to establish a new marketplace with Microsoft's closed-source operating system. Microsoft, with their business relationships, may actually float Nokia, with this unfortunate BlackBerry disaster.
This will surely be a feeding frenzy for the three major remaining phone operating system vendors.

Bad for the Free Market
The Free Market is all about choice - the loss of any major competitor in the market is bad for all of the consumers.
One might argue that RIM's "monopoly" of providing THE centralized infrastructure for all BlackBerries to traverse is the due penalty for their anti-capitalistic tendencies... and their customers deserve what they get for placing all their "eggs in one basket".
This author is not interested in seeing the diverse market competitors become centralized, since the evil is self-evident, it is dangerous for innovation. There must be freedom to innovate in the highly government regulated market of telecommunications.
Network Management
The probable decline of RIM is due to one massive network infrastructure error.
Had their network been better managed, their future decline may not be so sure.
It is possible that they will recover, but I would hate to be in that company today, and I would hate to be the team managing that network today.
The network is the rise and fall of a company - don't mis-manage your network.
Monday, October 10, 2011
Recovering From "rm -rf /"

Recovering From "rm -rf /"
A recent favorite blog offered a very nice introduction to the benefits of using ZFS as the root file system under Solaris.
This is every system administrator's worst nightmare, not to mention bad joke that gets giggles whenever such a mistake is suggested.
History
This condition is, perhaps, every operating system or application administrator's worst nightmare... the loss of a root or OS volume due to non-hardware, non-firmware, or non-OS caused related error.
Having seen an "rm" go out of control a number of years ago, due to a shell script which had an improperly initialized variable, this writer can say with a high degree of certainty that every time a shell script is written by a seasoned scripter, the paranoia from such a possibility will force consideration of whether this condition could EVER happen... often to the point of ensuring that there is no possiblity that an environment variable expansion could NEVER equate to "/" or even an entire user's home directory.

Benefits: Applications & Security
It is great to see first-class operating systems propose a solutions to a badly performed actions such as this... or just plain-old bad application patches. Sure, some utility writers will protect the "/" filesystem through hardcoded checks - but evil "rm -r" expansions can occur from "." and ".." and cause very similar kinds of damage.
Protecting root filesystems with ZFS offers a fast recoverable fallback. Protecting application filesystems with ZFS offers similar application level fallback. Protecting data with ZFS offers instantaneous (and virtually unlimited) backups, as well.
As a side note, this also provides a rollback mechanism for virus/worm infection, or intruder compromise, leaving Solaris with an incredibly important mechanism for security that is rivaled by few operating systems.
Conclusion
After reading multiple articles about the draconian methodology used by the U.S. military in dealing with PC rebuild times, due to not using freely available ZFS to roll back time on the desktops, one might think that using an operating system without such protections against viruses and worms is akin to a national security problem.
Friday, October 7, 2011
Astrolabe Cultists Nukes Science and History

Astrolabe Cultists Nukes Science and History
No good deed goes unpunished. What is a "labe", anyway? Who is the Astro?
How Network Management Systems Keep Time
At the core of every network management system is a critical component: time. ICMP and SNMP Polls are sent out according to a standard time interval. SNMP Traps are received on time intervals. Threshold crossings occur on certain time intervals. Reporting of these results, across timezones spanning a globe is quite complex.
If you have an alert in India, how do you know what the offset is from the reporting location? How does a web browser know the time offset from the web server location? When did the Daylight Savings Time change occur under President G.W. Bush across the various timezones in the United States? When a nation or city changes it's name - how does one know what time it is [before and after the name change] in those locations, in relation to the rest of the world?
Well, all of these political and geographic adjustments are kept in a timezone database.
A Short History of Time
It may be hard to wrap one's brain around why astrological cultists sued a coder who wrote software and key-punch operator who inserted information compiled from worldwide sources into a community database, free of charge, for decades of their life.
The timezone database dates back to at least November 24, 1986. As political changes occur, new versions of the database were published several times a year.
About 10 years later, Astrolabe advised Astro Computing Services on a Windows 3.1 PC user interface related to astrology, latitude, longitude, and timezones. (Microsoft Window 3.1 was released during March of 1992.) Astrolabe bought distribution rights to the ACS Windows 3.1 PC Atlas in 2008, which contains astrology information.
The Internet Engineering Task Force started the transition of the timezone database to international standards bodies on January 27, 2011. Arthur David Olston planned to retire from his unpaid position in managing the timezone database according to a post on slashdot on March 6, 2011.
Cultists at Astrolabe sent a letter to the retiring Arthur David Olston to take down the database from a U.S. government web site around May of 2011 (ironically, Astrolabe is unsure of the exact date, as per their court filing.) The cultist trolls at Astrolabe then filed a personal law suit against the retiring timezone keeper and the person who inserts new data into the database on September 30, 2011.
The mailing list was shut down on October 6, 2011. The FTP site, which contained information compiled by the community who participated in the mailing list was also shut down. Global systems with automated FTP accesses are now broken.
The open community reference for worldwide timezone information has been nuked. Clearly, this group who bought rights to a Windows 3.1 astrology program is little more than a useless copyright troll.
What Was Nuked: OUR Timezone History
Arthur David Olson, who wrote the code to parse the timezone database, has not earned a dime from his years of ongoing research and creation of the systematic timezone database that nearly all systems use world-wide - yet the cultists at Astrolabe are filing law suits against him, personally???
Paul Eggert, the contributor who made the "uniform naming convention" of [region]/[city] is also named personally in the law suit. He is the person who makes new changes to the database, as they are discovered world-wide from various political changes. How odd is suing an individual, who is making additions to a database???
To give you an understanding as to the scholarship of these individuals, one must read this from Jon Udell. There were many contributors to this database - the notes truly compose an interesting literary work, which goes back to the explanation of how and why time is accounted for today. For example, the blog included this particular quote from the nuked time database:
Erasing decades of history and shooting old people and keypunch operators, who are also scholars in their own right, are not ways for cultists to win converts.From Paul Eggert (2001-05-30):
Howse writes that Alaska switched from the Julian to the Gregorian calendar, and from east-of-GMT to west-of-GMT days, when the US bought it from Russia. This was on 1867-10-18, a Friday; the previous day was 1867-10-06 Julian, also a Friday. Include only the time zone part of this transition, ignoring the switch from Julian to Gregorian, since we can’t represent the Julian calendar.As far as we know, none of the exact locations mentioned below were permanently inhabited in 1867 by anyone using either calendar. (Yakutat was colonized by the Russians in 1799, but the settlement was destroyed in 1805 by a Yakutat-kon war party.) However, there were nearby inhabitants in some cases and for our purposes perhaps it’s best to simply use the official transition.
Call to Inquire of Purchase
If you need a timezone database, you should inquire if they have a substitute that adheres to the global TZ database standard for your software or operating system. If they don't offer a product for your operating system or adhering to the standard format, then tell them to get with the program.
Eastern Sales/Information: 1 (800) 843-6682
One can't definitively determine what "Eastern" time is, as labeled in their contact information page, since they nuked the timezone database. But one could always ask how they expect people to know what timezone they are in when their lawsuit was personally responsible for the removal of the timezone database from the internet.
Tech Support/Business Line: 1 (508) 896-5081
Hours 11am - 4pm
Hours 9:30am - 5:30pm
Eastern Fax: 1 (508) 896-5289
Snail Mail: Astrolabe Inc.
PO Box 1750
Brewster, MA 02631 USA
Some emails of interest.
Director of Marketing: Madalyn Hillis-Dineen
Technical Support: Support@alabe.com
Order questions: orders@alabe.com
Sales and nonTechnical questions: astrolabe@alabe.com
Webmaster: webmaster@alabe.com
Wednesday, October 5, 2011
Solaris 11 Preview (Part 2)
Solaris 11 Preview (Part 2)
Timothy Prickett Morgan from The Register wrote an excellent article "Oracle previews Solaris 11, due in November" which spurred some contemplations.
Solaris 11 Performance Features

In the "Pushing Solaris to 11" section, TPM talks about the features added to Solaris 11.
I honestly don't think that these features pushed out Solaris 11 release. Many of them appeared in Solaris 10 Update 10, so I don't think the Solaris 11 "extra time" was necessarily due to many of these features.One of the things that probably took some extra time was doing optimizations in Solaris specifically for Oracle software, which Fowler touched on here
Solaris 10 Update 10 Performance Features
Some of the features mentioned in the "New in Oracle Solaris 11" happened to make it into Solaris 10 Update 10 - which many in the market are very pleased about.
In particular, some of the items included: ISM, DISM, RDSv3, many improvements in various threading libraries.
Other features, not mentioned in the release notes, but mentioned in Solaris 10 Update 10 patch notes include: T4 support, low latency socket framework

[time slider illustration]
Solaris 11 Upgrade Features
TPM also mentioned Fowler speaking about upgrade ease.
Solaris 11 will, for instance, have one button rollback features so if customers don't like the results of their upgrade to Solaris 11With Solaris 11's integration with ZFS, multiple boot environments consume virtually no disk space, and upgrades can be done where the old boot environments may be allowed to remain in place (indefinitely, without losing OS mirroring capability), as with old Live Upgrade requirements. It just takes a keystroke to select the old boot environment under Solaris 10 Update 10 or Solaris 11.
There is an additional "time slider", which is part of OpenSolaris, Solaris 11 Express, Solaris 11, and various other Solaris derivative operating systems - being able to turn back time on a system is pretty wonderful. Fowler may have been alluding to this.
Solaris 10 Update 10 Upgrade Features
One of the features mentioned in the Solaris 10 Update 10 was the Live Upgrade of Solaris 10 using ZFS. I classified this as a "performance" enhancement, since Live Upgrade existed under Solaris 10 with easy rollback in the past, but it required a mirrored disk.
The Live Upgrade enhancement using ZFS is now here, for Solaris 11. The time-slider, from Solaris 11 is not.
Solaris 11 Preview (Part 1)
Solaris 11 Preview (Part 1)
Timothy Prickett Morgan from The Register wrote an excellent article "Oracle previews Solaris 11, due in November" which spurred some contemplations.
Fowler said that the current Solaris 10 tops out at 512 threads and a few terabytes of addressable main memory.This may have been what Fowler said, but I wonder how much of an impacts of threads and large memory really has on Solaris 10, today. For example, the T3-4, which was released some time back, already surpasses 512 threads, with Solaris 10 performing linearly.
It is therefore not a coincidence that last year's top-end Sparc T3-4 server, which had eight 16-core, 128-thread Sparc T3 processors topped out at four sockets.This years top-end SPARC T4-4 server halved the cores, halved the threads, maintained throughput, so the T4 processor could have been extended to 8 sockets with additional threads being added over the T3-4 platform. This being said, I think it was a coincidence. I don't really think the number of sockets is a Solaris issue. The math just does not suggest this conclusion.
I suspect the decision to top-out at 4 sockets has more to do with chip design realities. The decision to extend the cross-bar to manage another bit from 8 cores to 16 cores was a massive undertaking in the T3. The decision to extend add the S3 core into the T4 was a massive undertaking. The decision to integrate the massive S3 infrastructure onto the massive T3 crossbar will require more space, requiring a process shrink, which will also add significant effort.
Why does a process shrink require significant effort, when you are just making everything smaller? The answer to this question is related to another question which is always asked, "now that this is smaller, how much can we bump up the clock rate"?
The answer to this question deals with the length of the longest wires in the chip after the shrink - they are significant clock rate limiting factors. Any correction requires re-routing the "long" wires. The re-routing, by massive computing systems, absorb immense quantities of time. The chip testing, when adding functionality, also requires immense quantities of time.
These quantities of time are limiting factors. A single bug or manufacturing defect may require the turning-off of a feature (to be emulated in software, a-la Intel Floating Point bug) or a re-design of a chip area, without impacting surrounding areas.
Solaris 10 and 2011 Roadmaps
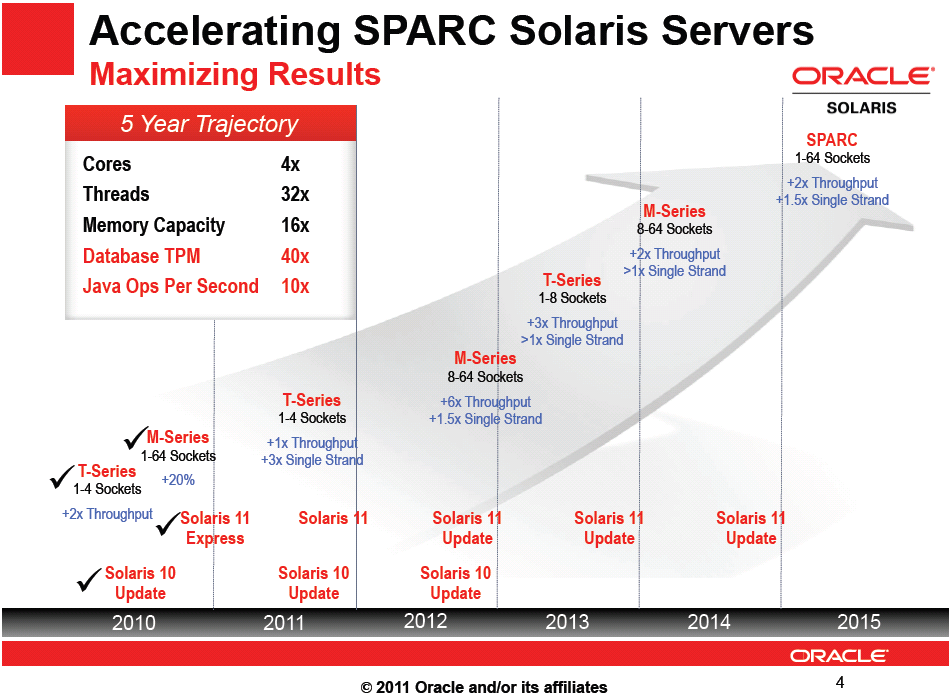
The early 2011 roadmap indicates Solaris 10 will experience a release in 2011 as well as 2012 - and the market just experienced Solaris 10 Update 10 release, according to the timeline provided.

The late 2011 roadmap did not show the on-time 2011 Solaris 10 release or the projected 2012 release... but there is an indication of the next T processor being pulled into the same timeframe as the 2012 Solaris 10 release.
Doing the math, it seems the "T5-8" platform (if Oracle remains consistent with their naming conventions) may really increase the number of simultaneous threads, and one might suspect that the 2012 projected "Solaris 10 Update 11" release might probably support the larger number of total number of threads.
2010 T3-4: 16 cores * 8 threads * 4 sockets = 1024 threadsConclusion:
2011 T4-4: 08 cores * 8 threads * 4 sockets = 0512 threads
2012 T5-8: 16 cores * 8 threads * 8 sockets = 2048 threads
The migration to Solaris 11 will probably take a long time. The market is pretty happy to see many Solaris 11 performance features being back-ported to Solaris 10, especially since Solaris 11 is not supported under older SPARC hardware. More on this in Part 2 of this series.
Subscribe to:
Posts (Atom)